時代はローカルLLMということで、ちょっと興味があったので、iOS/iPadOS上でローカルLLMを動かしてみた。
MiniAIChat
習作として、ローカルLLMを使った質問応答型のmacOSアプリを作った。ネイティブで書かれており、Apple Platformなら大体動く(Mac/iPhone/iPad/Apple Vision Pro)
質問応答
まずはオーソドックスな質問応答をさせている。ローカルLLMにしてはけっこうな精度で回答できていそう。
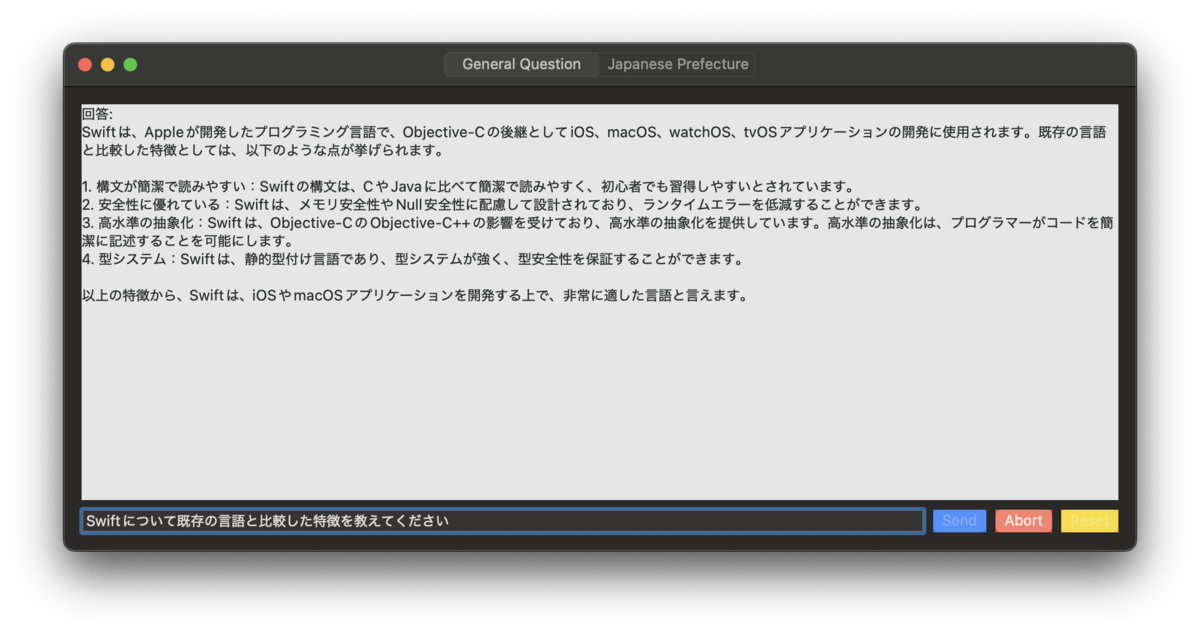
単に以下のようなプロンプトを与えている。後述の日本語LLMのサンプルを参考にしているが、このような催眠術に効果があるかはわからない。
あなたは誠実で優秀な日本人のアシスタントです。特に指示が無い場合は、次の質問に常に日本語で回答してください。 回答は「回答:」から始めて簡潔に答えてください。 \(text)
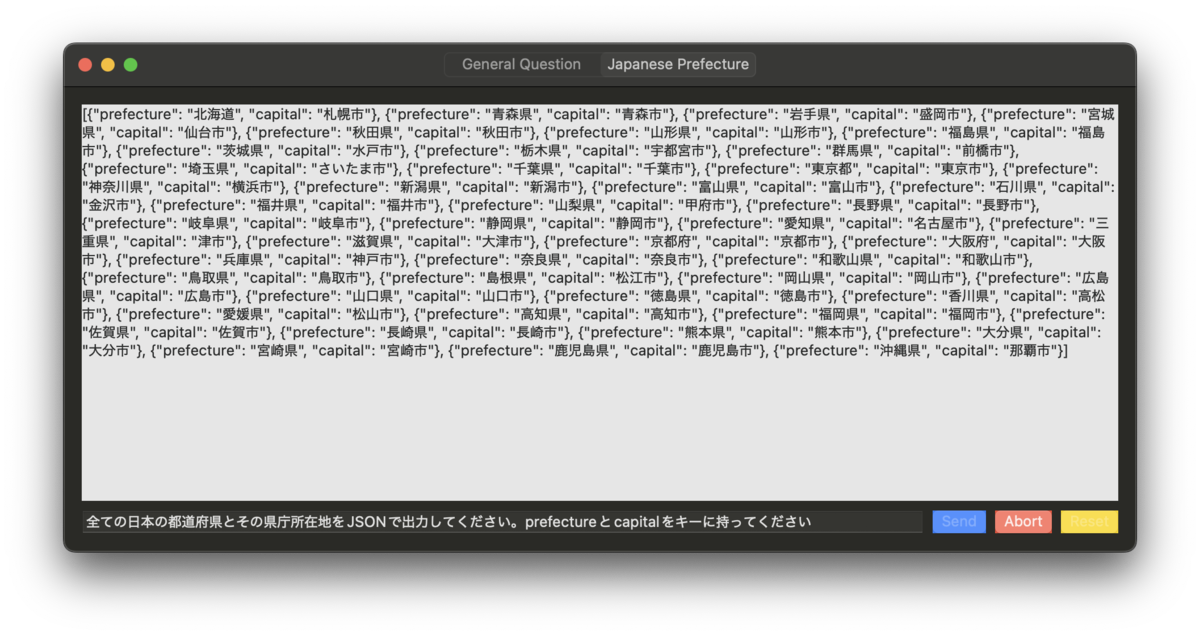
JSONの生成
手法については後述するが、特定のスキーマに適合したJSONの生成も試している。構造化データを吐き出すのに使えそう。
CoreML VS Llama
AppleプラットフォームのML基盤と言えば、CoreMLが真っ先に挙げられる。しかし、CoreML向けのLLM(日本語も)は充実していないし、他の既存モデルをCoreML上で動作させるには、coremltoolやHugging FaceのExportersを用いて、CoreML上で動作可能な形式に変換しなくてはならない。
ローカルLLMをCore MLモデルに変換する - 🤗 Exporters の使い方
この記事を書かれた @shu223 と先日飲んでいたところ、「CoreMLのモデル変換は知識がないとハマって難しい」という話を聞いたので、今回は直接LlamaをiOS上で動かしてみることにした。
Llama.cpp
Llama.cppはC++からLlamaを扱うためのライブラリ群だ。そしてなんとSwift Package版も提供されている。
これについて、さらに素晴らしい応用例の記事が既に存在してる 👏 今回はこれを大変参考にした。
基本的な話は上記の記事がほとんど網羅してくれている。概念を学んだり、試してみるのはこの記事を参考にすれば十分なはずだ。
一方で、この記事が書かれた2023年12月から比べて、細かな事情がいろいろと変わっていたので、この記事ではその差分や、ハマったところを中心に紹介する。
サンプルコードのキャッチアップ
Llama.cppには、SwiftUIで実装したサンプルアプリのコードが同梱されている。基本的にこれを参考にできるが、最低限の機能しか実装されていないため、上述のZennの記事のサンプルアプリも一緒に読み込んだ。
また、Swift実装だけでは不十分だったので、Llama.cppのリポジトリに同梱されている examples/simple-chat や common-sampler の実装も参考になった。
ドキュメントも他の実用例も不足しているので、C++のコードを読みながらSwiftに翻訳していく。上記の記事が書かれた1年前から、samplerなどLlama.cpp内の多くの実装が変更されていたので、PRなども参照しながら移植した。
LLMを選ぶ
基本的にHugging Faceから、Llama用のモデルを選び、差し替えるだけで動作させることができた。
今回、日本語のモデルとして、ELYZAが提供しているLlama 3のLLMを用いた。このモデルを使うと、日本語であってもそこそこの精度で質問応答をしてくれて、期待以上の返答が得られた。
日本語にこだわる必要がない場合は、Meta公式のLlamaのモデルを使うとよい。InstructionやCodeLlamaなどを用途に合わせて利用できそうだった。英語の方が精度も良い。
GBNFによる生成結果への制約
Llama.cppでは、GBNFという文法定義のフォーマットを使って、生成される文字列を制約する機能(Grammar)が提供されている。
root ::= answer answer ::= "回答:" message message ::= string+ ([ \t\n] string+)* string ::= alnum-char | jp-char alnum-char ::= [^"\\] | "\\" (["\\/bfnrt] | "u" [0-9a-fA-F] [0-9a-fA-F] [0-9a-fA-F] [0-9a-fA-F]) # escapes jp-char ::= hiragana | katakana | punctuation | cjk hiragana ::= [ぁ-ゟ] katakana ::= [ァ-ヿ] punctuation ::= [、-〾] cjk ::= [一-鿿]
JSON Schemaを使ってGBNFを生成する方法も用意されており、これらを正しく実装すると*1、validなJSONをLLMに吐かせることができた。
オンラインコンバーターも提供されていたので、この辺を差し替えるだけで、先述のJSONの生成のような、わりとそれっぽいモノができた。正規化データができてしまえば、いろいろ応用が利きそうだ。
先述の記事の段階では、Llama.cppのライブラリ部分にGBNFのパーサーがなく、本体のコードを移植しなおすなど、ハックが必要だったようだが、本稿執筆時点では、GBNFのパーサー部分がライブラリとして提供されるようになったようで、記事で触れられているような手法を採らずともGrammarの生成が行えた。
トークン生成のAsyncSequence対応
Llama.cppに同梱されているSwiftのサンプル実装ではactorを用いて、生成状態を監視して無限ループするという実装になっているが、どうにも扱いづらいAPIなので、AsyncSequenceを使ったものに書き換えてみた。
let session: some AsyncSequence = llamaContext.startGeneration(for: prompt) Task { for try await result in session { guard !Task.isCancelled else { break } guard case .piece(let newPiece) = result else { break } await MainActor.run { self.text += newPiece } } }
パッと見、外からの使い勝手は良くなったように思えるが、結局Sequenceの内部はUnsafePointerの操作を隠蔽しているのであまり綺麗になっていない。
トークンは非同期に数文字ずつ生成されるので、Asyncに扱うための格好の題材だ。0からSequenceやIteratorを書くことも少ないので、Mastering AsyncSequenceを読み直す機会にもなって良かった。
所感
Llama.cppとC++ interoperability
近年のSwiftでは、C++ interoperabilityがサポートされ、C++のライブラリもある程度そのまま扱えるようになってきている。一方で、現状のLlama.cppのSwift Packageは、PackageDescriptionが5.5と古く、C++ Interopを提供していない。そのため、実質的にはCインターフェイスしか読めず、UnsafePonterでAPIをゴリゴリと操作する必要がある。(つらかった)
Swiftパッケージ側をモダン化すれば、C++の構造体やクラスなどを直接Swift側で操作できるようになるので、ある程度使い勝手は良くなりそう・・・・・・。
Llama.cppのバージョニング問題
上記の AsyncSequence 化など、せっかく書いたので、もっとSwiftから扱いやすい形でライブラリを提供しようかと考えていたが、Llama.cpp自体に依存するのは現状危なそうに思えた。
Llama.cppにあまりドキュメントがないことに加え、semverを採用しておらず、今現在もドラスティックに実装が変更されているためだ。現に、最初に紹介した記事からわずか1年で多くの公開APIが変更されていた。
今回は学習のためのトイプロジェクトなので、メンテナンス性などを考え、一旦これ以上の発展を諦めた。
AppleデバイスとローカルLLM
開発の大部分はmacOS向けのビルドで行っていたが、実機(iPhone 16 Pro, iPad Pro(M4))でローカルLLMを動かしてみると、先述のELYZAのLlama 3モデルをはじめ、多くのLLMは純粋にメモリ不足で動かなかった。Llama3のモデルは4bit量子化のモデルしか提供されておらず、これが最小サイズなので、実機で動かすにはLlama 2.7のモデルを使うしかなかった。
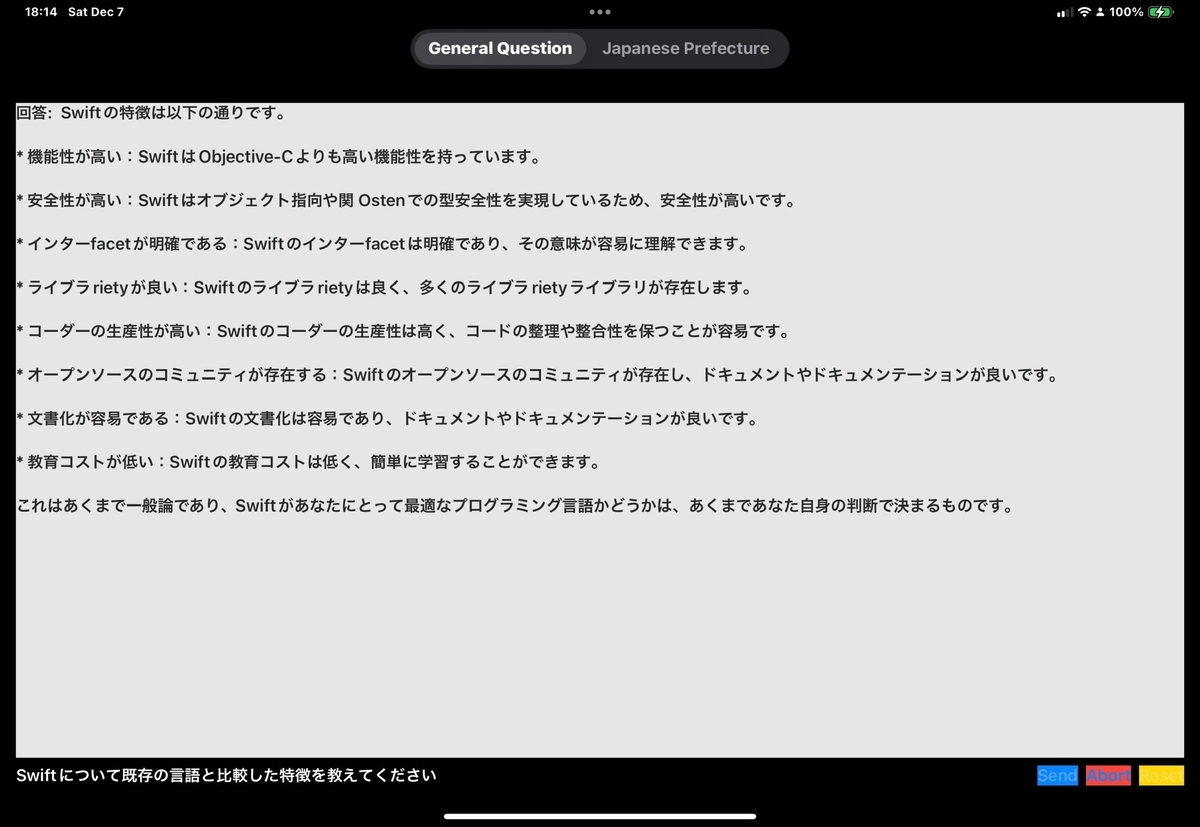
実機で利用可能なモデルは日本語だとご覧の通りの精度しか出ないため、実用にはほど遠い。その上、ユーザーに2GBものストレージも要求してしまう。汎用LLMは現時点では実用に耐えないだろう。
エンドユーザーからすると「スマホやタブレットにそんなにメモリいらんやろ」と考えていたけど、ローカルLLMをまともな精度で動かすには、現状、全くRAMが足りてないことがわかった。今年出たばかりのiPad Pro(M4)ですら8GB*2で全然足りない。
一方で、MacBookと同じチップを載せているiPadのMシリーズはもちろん、現行のiPhoneのAシリーズでも計算リソースは十分に見えた。計算量よりもRAMがボトルネックになっているのは直感に反していて面白い。
おわりに
休日1日 + αぐらいでLlama.cppの実装を読んだり、LLMについて簡単に学べた。特に、現状だとやはりオモチャ以上には使い物にならないという点が肌感を持って理解できたのは良かった。
LLMについても、現状の限界や、形式・量子化の手法など、いくつかキャッチアップすることができた。とはいえ、僕は機械学習については素人なので、肝心なモデルがどのように学習されているか、という部分については全く知識がない。この辺がブラックボックスになっているのは危ういなと感じつつも、全ては押さえきれないなという気持ちもある。
体験としては、3Dモデリングができずとも、Unityを使って拾ってきた素材でなんとなくゲームができるといった感覚に近かった。
Llama.cppの習得については、上記の記事以外にほとんど情報がなく、ドキュメンテーションも乏しいので、この記事が興味のある方の役に立てば幸い。